





.webp)

The Data Behind the Fire: A Look Into Our Wildfire Model
Wildfires now result in nearly 6 million more hectares of tree cover loss per year than in 2001, an area the size of Croatia.
Feb 19, 2026
Exposure data sits at the heart of effective catastrophe and hazard modelling. Yet anyone who has worked with large Schedule of Values (SOV) datasets knows that preparing this information for modelling can be one of the most time-consuming steps in the workflow. Inconsistent formats, incomplete fields, duplicated entries, and poorly structured address data often create significant delays before meaningful analysis can even begin.
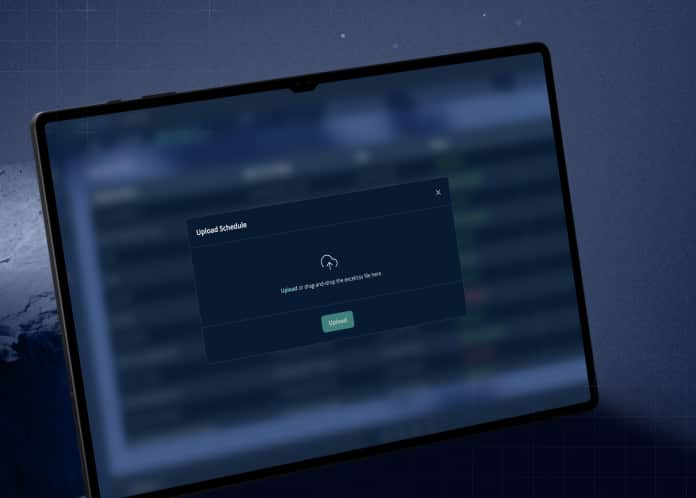
To address this challenge, we’re excited to introduce AI Data Scrubbing, our newest tool designed to automate the cleaning and geolocation of exposure data at scale. The goal is simple: help teams move from raw SOV files to modelling-ready datasets faster and with far less manual intervention.

The Data Challenge in Exposure Modelling
Exposure datasets frequently arrive in Excel spreadsheets compiled from multiple sources—brokers, policy systems, coverholders, or internal underwriting tools. While these datasets contain critical information about insured assets, they often lack the standardisation required for hazard modelling platforms.
Common issues include:
These problems can quickly compound when working with large portfolios, turning what should be a straightforward step into a significant operational bottleneck.
Automating the Data Preparation Process
AI Data Scrubbing is designed to remove much of this friction by using artificial intelligence to automatically clean, standardise, and geolocate SOV datasets. Once an exposure file is uploaded, the tool processes the data and transforms it into a structured, modelling-ready format.
Instead of spending hours manually reviewing spreadsheets, exposure teams can focus on analysis and risk insight while the system handles the underlying data preparation.

Key Capabilities
The first release of AI Data Scrubbing includes several core capabilities designed specifically for exposure modelling workflows:
Built for Exposure and Risk Teams
AI Data Scrubbing has been developed with the needs of insurers, brokers, coverholders, and exposure management teams in mind. By automating the early stages of the modelling pipeline, the tool helps remove operational bottlenecks and enables faster movement from raw exposure data to actionable risk insights.
For organisations managing large portfolios or frequently receiving new SOV submissions, this can significantly improve efficiency and consistency across modelling workflows.
A Collaborative Beta Phase
AI Data Scrubbing is currently being released in beta, and we are actively working with early users to refine the platform. Feedback during this phase will help shape future functionality, improve data handling accuracy, and expand capabilities as the tool evolves.
Our goal is to build a system that not only automates data preparation but also becomes an integral part of the exposure modelling workflow for risk professionals.

BirdsEyeView Secures Seven-Figure Investment to Accelerate Global Expansion
BirdsEyeView, the European Space Agency-backed insurtech specializing in natural catastrophe modelling and exposure management, has secured an undisclosed seven-figure investment to support the company’s continued international growth and ongoing product development.

Have questions about CERA®, integrations, pricing, or use cases for your organization? Our specialists can walk you through the platform and recommend the right solution.
